

Introduction: The Hidden Engine Behind Modern AI
If you’ve been following recent developments in artificial intelligence, you’ve probably seen the term AI model distillation showing up more often. It gained wider attention after Anthropic revealed large-scale attempts to extract capabilities from its Claude models using structured queries. for more
At first glance, model distillation sounds like a technical optimization method. And in many cases, it is. But in 2026, it has become something much bigger. It now sits at the center of debates around intellectual property, AI safety, and even national security.
This article breaks it down clearly. No jargon, no hype. Just how it works, why companies use it, and why it’s becoming controversial.
What Is AI Model Distillation?
Model distillation is a technique where a smaller AI model is trained to replicate the behavior of a larger, more powerful model.
In simple terms:
- A large model (called the teacher) already knows how to perform complex tasks
- A smaller model (called the student) learns by observing the teacher’s outputs
- The goal is to create a model that is faster, cheaper, and easier to deploy
Instead of training a model from scratch using massive datasets, developers use the teacher’s responses as a shortcut.
A Simple Analogy
Think of it like this:
- The teacher is an experienced professor
- The student is a new learner
- Instead of reading hundreds of textbooks, the student studies the professor’s answers directly
This approach saves time, cost, and computing power.
Why Distillation Exists in the First Place
Training large AI models is extremely expensive.
For example:
- Training a frontier model can cost millions of dollars in compute
- It requires specialized hardware like high-end GPUs
- It takes weeks or months of continuous processing
Distillation solves a practical problem:
How do you bring powerful AI capabilities to smaller devices or cheaper systems?
Key Benefits of Distillation
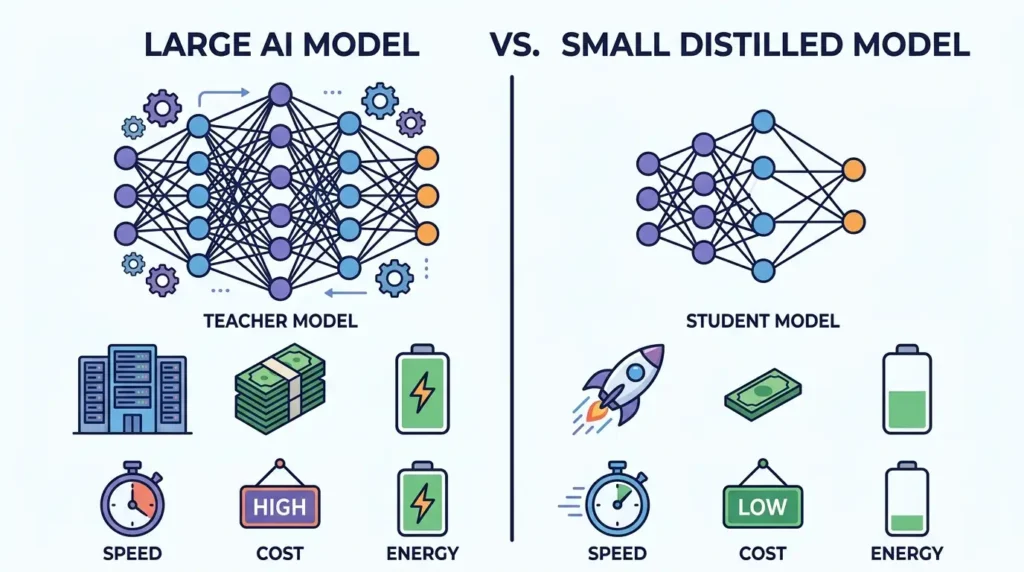
1. Lower Costs
Smaller models require less computing power, which reduces infrastructure costs.
2. Faster Performance
Distilled models run faster, making them suitable for real-time applications.
3. Edge Deployment
They can run on smartphones, browsers, or embedded systems.
4. Energy Efficiency
Less compute means lower energy consumption.
These benefits are why nearly every major AI company uses distillation internally.
How AI Model Distillation Works (Step-by-Step)
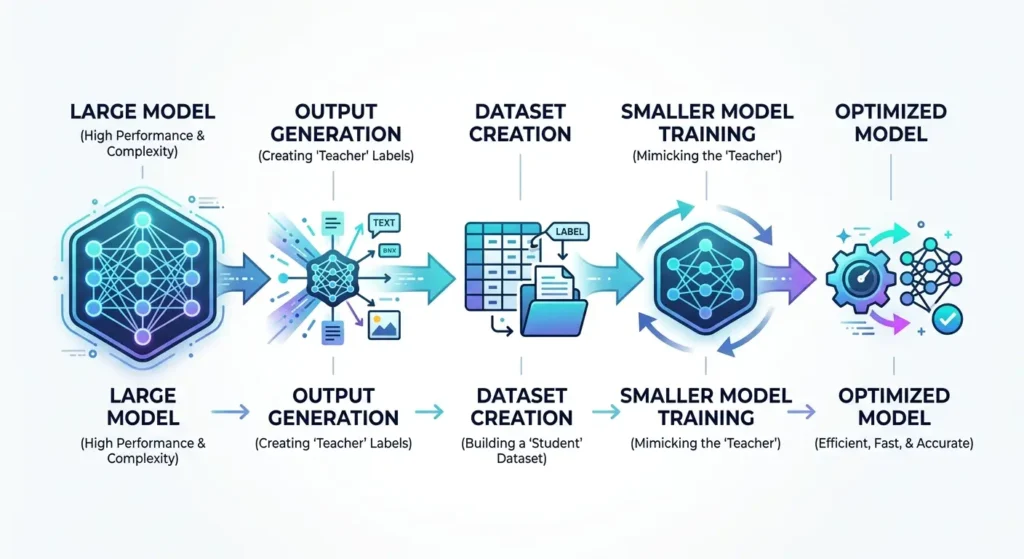
Let’s walk through the actual process in a simplified way.
Step 1: Start with a Trained Teacher Model
This is usually a large language model like those developed by companies such as OpenAI or Google DeepMind.
These models are trained on massive datasets and can perform complex reasoning tasks.
Step 2: Generate Outputs from the Teacher
Developers feed the teacher model a wide range of prompts:
- Questions
- Instructions
- Scenarios
The teacher produces high-quality responses.
Step 3: Collect the Outputs as Training Data
Instead of using raw internet data, the student model learns from:
- The teacher’s answers
- The structure of those answers
- The reasoning patterns (in some cases)
This is often called synthetic data generation.
Step 4: Train the Student Model
The smaller model is trained to mimic the teacher’s behavior.
It learns:
- How to respond
- How to structure answers
- How to approximate reasoning
Step 5: Optimize for Efficiency
After training, the model is optimized for:
- Speed
- Memory usage
- Deployment constraints
Legitimate vs Illicit Distillation: Where the Line Is Drawn
Distillation itself is not illegal. It’s widely used across the industry.
The controversy begins when companies use models they don’t own.
Legitimate Distillation
This happens when:
- A company distills its own models
- Proper licenses are followed
- Data usage complies with terms of service
Example:
A company trains a large model and creates a smaller version for mobile apps.
Illicit Distillation (Capability Extraction)
This is what raised concerns in recent reports involving DeepSeek, Moonshot AI, and MiniMax.
It involves:
- Querying a competitor’s model at scale
- Collecting outputs without permission
- Training a competing model using those outputs
This is often described as:
Extracting the knowledge embedded in another company’s model
Why This Is Hard to Detect
Unlike traditional data theft, distillation doesn’t involve stealing files.
Instead:
- The attacker interacts with a public API
- The data is generated in real time
- Each request looks normal in isolation
Detection becomes difficult because:
- APIs are designed to be accessible
- High usage doesn’t always mean malicious intent
- Patterns only emerge at large scale
The Role of APIs in Distillation Attacks
Modern AI systems are often accessed through APIs.
These APIs allow developers to:
- Send prompts
- Receive model outputs
- Build applications on top of AI
But this convenience creates a vulnerability.
Why APIs Are the Weak Point
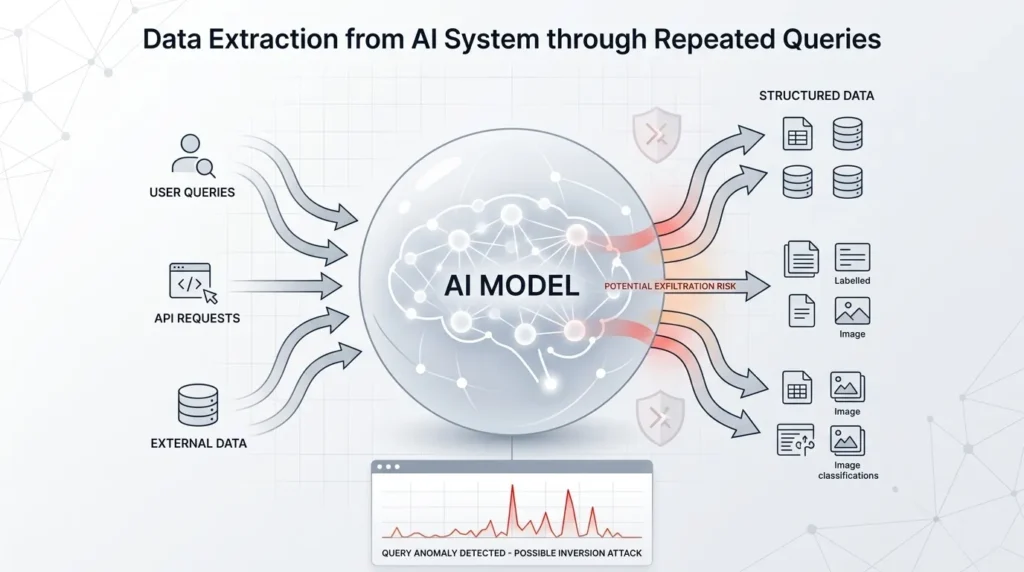
- They expose model behavior
- They allow automated querying
- They scale easily with scripts
At large volumes, APIs can be used to:
- Map how a model responds
- Reconstruct its capabilities
- Generate massive training datasets
The Scale Problem: Why Volume Matters
A few hundred queries won’t replicate a model.
But millions of structured queries can.
Large-scale operations:
- Use automation
- Generate diverse prompts
- Cover multiple domains
This creates a dataset that captures:
- Language patterns
- Reasoning styles
- Output structures
At that point, the student model begins to approximate the teacher.
Why AI Companies Are Concerned
The issue isn’t just competition. It’s about:
1. Intellectual Property
AI models represent:
- Years of research
- Large financial investments
- Proprietary techniques
Distillation can bypass these investments.
2. Safety Risks
Leading AI labs spend significant resources on:
- Content moderation
- Safety guardrails
- Risk mitigation
Distilled models may:
- Replicate capabilities
- Lose safety constraints
This creates potential misuse risks.
3. Competitive Advantage
If smaller players can replicate frontier models:
- Barriers to entry drop
- Market dynamics shift rapidly
The Watermarking Defense: A New Approach
To counter unauthorized distillation, companies are exploring watermarking.
What Is AI Watermarking?
It involves embedding subtle statistical patterns into model outputs.
These patterns are:
- Invisible to users
- Detectable through analysis
How It Works
- The model slightly biases word choices
- These biases form a hidden signature
- If another model reproduces the same patterns, it suggests copying
Why It Matters
Watermarking can:
- Provide evidence of misuse
- Support legal claims
- Act as a deterrent
However, the exact effectiveness is still being studied. I cannot confirm that watermarking alone can fully prevent distillation.
The Legal Gray Area
Current laws were not designed for AI models.
Key questions include:
- Can AI outputs be considered intellectual property?
- Is learning from outputs equivalent to copying code?
- How do you prove a model was trained on another model’s responses?
Legal systems are still catching up.
National Security Implications
Distillation is no longer just a technical issue.
It intersects with:
- Global AI competition
- Export controls on hardware
- Strategic technological advantage
Even if access to advanced chips is restricted, distillation can:
- Reduce compute requirements
- Enable faster replication of capabilities
The Future of AI: Toward Closed Systems?
As risks increase, companies may shift toward:
1. Stricter Access Controls
- Identity verification
- Usage limits
2. Reduced Transparency
- Less open APIs
- More restricted capabilities
3. Industry Collaboration
- Shared threat intelligence
- Standardized defenses
What This Means for Developers and Businesses
If you use AI tools, this affects you.
Expect:
- More API restrictions
- Higher costs for access
- Stronger compliance requirements
For AI Builders:
- Security will become a core feature
- Monitoring usage will be essential
Key Takeaways
- Model distillation is a legitimate and widely used AI technique
- It allows smaller models to replicate larger ones efficiently
- The controversy arises when it’s used without permission
- APIs are a major vulnerability for large-scale extraction
- Companies are developing defenses like watermarking and behavioral detection
- Legal and regulatory frameworks are still evolving
Final Thoughts
Model distillation is not inherently good or bad. It’s a powerful tool.
What matters is how it’s used.
Right now, the industry is entering a phase where:
- Technical innovation is colliding with legal boundaries
- Open access is clashing with security concerns
- Efficiency gains are raising ethical questions
How these tensions are resolved will shape the future of AI.

Michael L. has spent the last 10 months writing about AI for people who never planned to care about it. He tests tools, cuts through the hype, and explains what actually works for everyday life and small business. No tech background required.

