
Introduction: The Moment AI Security Changed

The AI model extraction attack revealed in 2026 marks a turning point in AI security. Instead of hacking systems directly, attackers used millions of API queries to reverse-engineer advanced models.
According to Anthropic, it detected and disrupted industrial-scale model extraction campaigns involving roughly:
- 16 million structured queries
- 24,000 coordinated accounts
The targets were its Claude models. The alleged actors included DeepSeek, Moonshot AI, and MiniMax.
This activity has been widely reported and analyzed by cybersecurity outlets such as
This wasn’t a typical cyberattack. No servers were breached. No code was stolen.
Instead, the attackers used a far more subtle method:
They asked the model questions. Millions of them.
This article explains, step by step, how such an operation works, why scale is everything, and what it reveals about the future of AI security.
What Is an AI Model Extraction Attack?
At its core, this type of attack relies on a simple idea:
If you can’t access the model directly, learn from its behavior.
Modern AI systems are exposed functionality through APIs. These APIs allow anyone with access to:
- Send prompts
- Receive responses
- Build applications
However, research has shown that these interactions can also be exploited. Studies on query-based model extraction attacks demonstrate that attackers can replicate models using only API outputs.
The Core Mechanism
A query-based extraction attack involves:
- Sending large volumes of carefully designed prompts
- Collecting the model’s outputs
- Using those outputs to train a separate model
Over time, the attacker builds a dataset that reflects how the original model thinks.
Why 16 Million Queries Is a Big Deal

A few thousand queries won’t replicate a model.
Even a few hundred thousand may not be enough.
However, millions of structured queries change the equation.
Each query produces an output, and at scale, this creates a massive dataset. This dataset can then be used to train another model.
Research into neural network extraction confirms that large query volumes significantly improve reconstruction accuracy.
Step-by-Step Reasoning
Let’s break it down:
- Each query produces an output
- That’s one data point
- 16 million queries = 16 million data points
- This becomes a large synthetic dataset
- If prompts are diverse and structured
- The dataset covers multiple domains and tasks
- Training on this dataset
- A smaller model starts approximating the original
This is why scale matters more than anything else.
How the Attack Likely Worked (Reconstructed Process)
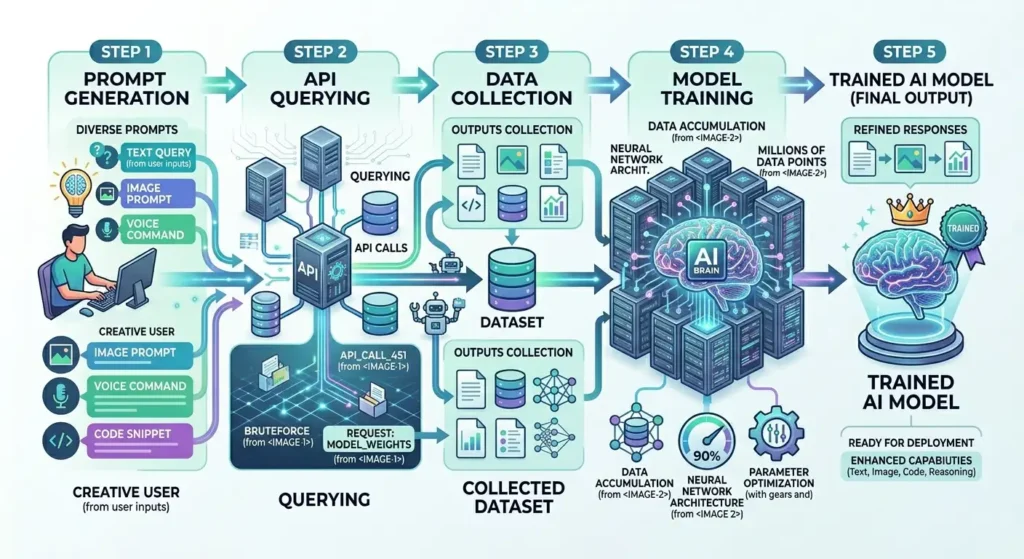
While exact technical details are not fully public, the general process can be reconstructed based on known AI practices and the reported data.
Phase 1: Prompt Generation at Scale
Attackers don’t manually write millions of prompts.
They use automation to generate:
- Question variations
- Task instructions
- Edge-case scenarios
These prompts are designed to:
- Cover a wide range of topics
- Trigger different reasoning patterns
- Extract structured outputs
Phase 2: Automated Querying
Scripts send prompts through the API continuously.
Key characteristics:
- High frequency
- Distributed across accounts
- Often masked to appear human-like
The use of 24,000 accounts suggests:
- Attempts to bypass rate limits
- Avoid detection thresholds
- Maintain continuous access
Phase 3: Output Collection and Structuring
Every response is stored.
But raw data isn’t enough. It must be organized.
Typical processing includes:
- Cleaning outputs
- Removing noise
- Structuring into training format
At this stage, the attacker has:
A massive, labeled dataset generated by the target model
Phase 4: Training the Student Model
This dataset is used to train a smaller model.
The model learns:
- Language patterns
- Response structures
- Approximate reasoning behavior
This process is closely related to knowledge distillation, but without authorization.
Phase 5: Iterative Improvement
The process doesn’t stop after one round.
Attackers can:
- Identify weak areas in the student model
- Generate new targeted queries
- Refine the dataset
This feedback loop improves accuracy over time.
The Role of Structured Queries
Not all queries are equally valuable.
Random prompts produce random outputs.
But structured prompts:
- Target specific capabilities
- Extract consistent patterns
- Improve training quality
Examples of Structured Query Types
- Multi-step reasoning questions
- Code generation tasks
- Instruction-following prompts
- Edge-case scenarios
These help capture how the model handles:
- Logic
- Context
- Constraints
Why This Doesn’t Look Like a Traditional Attack
This is what makes detection difficult.
There is:
- No malware
- No unauthorized server access
- No direct data breach
Everything happens through legitimate channels:
- Public APIs
- Standard requests
- Valid responses
The Key Difference
Traditional attacks:
- Steal data directly
Extraction attacks:
- Reconstruct knowledge indirectly
Detection: How Companies Spot These Patterns
To detect such activity, companies analyze behavior at scale.
1. Statistical Patterns
Normal users:
- Ask varied, inconsistent questions
- Have irregular timing
Automated systems:
- Generate consistent patterns
- Operate at high frequency
- Show repetitive structures
2. Account Coordination
The use of thousands of accounts is a signal.
Indicators include:
- Similar query types across accounts
- Synchronized activity patterns
- Shared infrastructure signals
3. Chain-of-Thought Elicitation
Some queries attempt to extract reasoning steps.
This can include:
- Asking the model to “explain step by step”
- Forcing detailed outputs
Monitoring for these patterns helps identify extraction attempts.
Why APIs Are the Weak Point
AI APIs are designed for accessibility.
That’s their strength and their weakness.
Key Reasons
- Open Access Model
- Developers need easy access to build applications
- Scalability
- APIs are built to handle large volumes
- Automation-Friendly
- Scripts can interact with APIs easily
The Trade-Off
More openness → more innovation
More openness → more risk
The Economics Behind the Attack
This type of operation is not free.
Let’s break it down logically.
Cost Factors
- API usage fees
- Infrastructure for automation
- Data storage and processing
- Model training costs
Why It Can Still Be Worth It
Training a frontier AI model from scratch:
- Requires massive compute resources
- Can cost millions
Extraction-based approaches:
- Reduce data collection costs
- Lower training requirements
- Accelerate development timelines
Even with API costs, the overall expense may be significantly lower.
I cannot confirm exact cost comparisons because they depend on pricing models and infrastructure efficiency.
Safety Risks: Why This Goes Beyond Competition
One of the biggest concerns is safety.
Leading AI companies invest heavily in:
- Content filtering
- Harm prevention
- Responsible behavior constraints
The Risk
A distilled model may:
- Retain capabilities
- Lose safety guardrails
This creates potential for:
- Misuse
- Unsafe outputs
- Reduced accountability
The Watermarking Countermeasure
To combat extraction, companies are exploring watermarking.
Concept
Outputs contain subtle statistical signals.
If another model reproduces these signals:
- It may indicate training on those outputs
Limitations
- Watermarks can potentially be diluted
- Detection is probabilistic, not absolute
- Techniques are still evolving
I cannot confirm that watermarking alone is sufficient to stop large-scale extraction.
Industry Response: What Changes Next
Following these developments, several shifts are likely.
1. Aggressive Rate Limiting
- Restrict high-volume usage
- Limit automated querying
2. Identity Verification
- Stronger account verification
- Reduced ability to create fake accounts
3. Behavioral Monitoring
- Real-time detection systems
- Automated blocking of suspicious activity
4. Reduced Transparency
- Less exposure of internal reasoning
- Controlled output formats
The Bigger Picture: A New Type of AI Conflict
This isn’t just a technical issue.
It reflects a broader shift in how AI competition works.
Instead of:
- Building models independently
We are seeing:
- Attempts to replicate capabilities through interaction
This creates tension between:
- Openness vs control
- Innovation vs protection
- Accessibility vs security
What This Means for Developers
If you rely on AI APIs, expect changes.
Likely Impacts
- Stricter usage limits
- More compliance requirements
- Increased monitoring
What You Should Do
- Optimize API usage efficiency
- Avoid unnecessary high-volume queries
- Follow platform policies carefully
Key Takeaways
- The “16 million query attack” represents large-scale model extraction via APIs
- Scale and structure are what make these attacks effective
- Detection relies on behavioral and statistical analysis
- APIs are the primary vulnerability in modern AI systems
- Defensive strategies are still evolving
- The issue has implications for security, economics, and global competition
Final Thoughts
This event marks a turning point.
AI systems are no longer just tools. They are assets worth protecting at scale.
The methods used in this case show that:
- You don’t need direct access to a model to learn from it
- Behavior alone can be enough to reconstruct capabilities
- Security in AI is now as important as performance
What happens next will define how open or restricted AI becomes in the coming years.

